DISTRIBUCIONES.
DISTRIBUCION NORMAL
En estadística y probabilidad se llama distribución
normal, distribución de Gauss o distribución gaussiana, a una
de las distribuciones de probabilidad de variable continua que con más
frecuencia aparece aproximada en fenómenos reales.
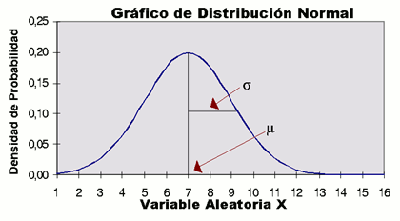
La gráfica de su función de densidad tiene una
forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva
se conoce como campana de Gauss y es el gráfico de una función gaussiana.
La importancia de esta
distribución radica en que permite modelar numerosos fenómenos
naturales, sociales y psicológicos. Mientras que los mecanismos que subyacen a
gran parte de este tipo de fenómenos son desconocidos, por la enorme cantidad
de variables incontrolables que en ellos intervienen, el uso del modelo normal
puede justificarse asumiendo que cada observación se obtiene como la suma de
unas pocas causas independientes.
De hecho, la estadística es un
modelo matemático que sólo permite describir un fenómeno, sin explicación
alguna. Para la explicación causal es preciso el diseño experimental, de
ahí que al uso de la estadística en psicología y sociología sea conocido como método
correlacional.
La distribución normal también
es importante por su relación con la estimación por mínimos cuadrados, uno de los
métodos de estimación más simples y antiguos.
Algunos ejemplos de variables
asociadas a fenómenos naturales que siguen el modelo de la normal son:
- caracteres morfológicos de individuos como la estatura;
- caracteres fisiológicos como el efecto de un fármaco;
- caracteres sociológicos como el consumo de cierto producto por un mismo grupo de individuos;
- caracteres psicológicos como el cociente intelectual;
- nivel de ruido en telecomunicaciones;
- errores
cometidos al medir ciertas magnitudes;
- etc.
La distribución normal también
aparece en muchas áreas de la propia estadística. Por ejemplo, la distribución muestral de las medias muestrales es aproximadamente
normal, cuando la distribución de la población de la cual se extrae la muestra
no es normal.
Además, la distribución normal maximiza la entropía entre todas las
distribuciones con media y varianza conocidas,
lo cual la convierte en la elección natural de la distribución subyacente a una
lista de datos resumidos en términos de media muestral y varianza. La
distribución normal es la más extendida en estadística y muchos tests
estadísticos están basados en una supuesta "normalidad".
En probabilidad, la
distribución normal aparece como el límite de varias distribuciones de
probabilidad continuas y discretas.| Distribución normal | |
|---|---|
 La línea verde corresponde a la distribución normal estándar Función de densidad de probabilidad | |
 Función de distribución de probabilidad | |
| Parámetros |   |
| Dominio |  |
| Función de densidad (pdf) |  |
| Función de distribución (cdf) |  |
| Media |  |
| Mediana | |
| Moda | |
| Varianza |  |
| Coeficiente de simetría | 0 |
| Curtosis | 0 |
| Entropía |  |
| Función generadora de momentos (mgf) |  |
| Función característica |  |
TEOREMA DE LA
COMBINACIÓN LINEAL DE VARIACIONES NORMALES Y CHI-CUADRADAS.
Terorema de Chebshev, este teorema da una
estimación conservadora de la probabilidad de que una variable aleatoria tome
un valor dentro de k dentro de k desviaciones estándar de su media para
cualquier número real k. Proporcionaremos solo la demostración para caso
continuo.
La probabilidad de que cualquier variable aleatoria X tome un valor dentro de k desviaciones estándar de la media es al menos 1-
DISTRIBUCIONES
MUÉSTRALES.
Las muestras aleatorias obtenidas de una población son, por naturaleza
propia, impredecibles. No se esperaría que dos muestras aleatorias del mismo
tamaño y tomadas de la misma población tenga la misma media muestral o que sean
completamente parecidas; puede esperarse que cualquier estadístico, como la
media muestral, calculado a partir de las medias en una muestra aleatoria,
cambie su valor de una muestra a otra, por ello, se quiere estudiar la
distribución de todos los valores posibles de un estadístico. Tales
distribuciones serán muy importantes en el estudio de la estadística
inferencial, porque las inferencias sobre las poblaciones se harán usando
estadísticas muestrales. Como el análisis de las distribuciones asociadas con
los estadísticos muestrales, podremos juzgar la confiabilidad de un estadístico
muestral como un instrumento para hacer inferencias sobre un parámetro
poblacional desconocido.
Como los valores de un estadístico, tal como x, varían de una muestra
aleatoria a otra, se le puede considerar como una variable aleatoria con
su correspondiente distribución de frecuencias.
La distribución de frecuencia de un estadístico muestral se denomina
distribución muestral. En general, la distribución muestral de
un estadístico es la de todos sus valores posibles calculados a partir de
muestras del mismo tamaño.


- La media poblacional es:
-


- La desviación estándar de la población es:
-


- A continuación se listan los elementos de la distribución muestral de la media y la correspondiente distribución de frecuencias.




| En la generalidad de los casos, no disponemos de la desviación standard de la población, sino de una estimación calculada a partir de una muestra extraída de la misma y por lo tanto no podemos calcular Z. | |||||||||||
| En estos casos calculamos el estadístico T: |
 | ||||||||||
| donde S es la desviación standard muestral, calculada con n-1
grados de libertad. Nótese que utilizamos S, la Desviación Standard de una Muestra, en lugar de μ, la Desviación Standard de la Población. El estadístico T tiene una distribución que se denomina distribución T de Student, que está tabulada para 1, 2, 3, ... etc. grados de libertad de la muestra con la cual se calculó la desviación standard. La distribución T tiene en cuenta la incertidumbre en la estimación de la desviación standard de la población, porque en realidad la tabla de T contiene las distribuciones de probabilidades para distintos grados de libertad. La distribución T es mas ancha que la distribución normal tipificada Para un número de grados de libertad pequeño. Cuando los grados de libertad tienden a infinito, la distribución T tiende a coincidir con la distribución normal standard. Es decir, en la medida que aumentemos el número de observaciones de la muestra, la desviación standard calculada estará mas próxima a la desviación standard de la población y entonces la distribución T correspondiente se acerca a la distribución normal standard. El uso de la distribución T presupone que la población con que estamos trabajando tiene una distribución normal. Distribución de Promedios Muestrales Para comprender que significa distribución de promedios muestrales, vamos a suponer que realizamos un experimento con bombos como los usados en la lotería. Colocamos un número muy grande de bolas blancas en un bombo blanco, en cada una de las cuales figura un dato X. Este bombo representa la población de observaciones X, y tiene media m y varianza s2. Supongamos que a continuación hacemos los siguiente:
2) Calculamos la media y la anotamos en una bola azul. 3) Colocamos la bola azul en un segundo bombo de color azul. 4) Devolvemos las bolas blancas a su bombo y le damos vueltas. 5)Repetimos toda la operación muchas veces hasta que el bombo azul esté lleno de bolas azules. Por lo tanto, si la muestra es mas grande (n mayor), estaremos en una distribución de promedios con desviación standard mas pequeña, por lo cual, el promedio de la muestra estará mas cerca del promedio del universo. Es por esto que es razonable pensar que el promedio de la muestra es una estimación del promedio del universo. DISTRIBUCIONES. NORMAL DOS PARÁMETROS
DISTRIBUCIONES. F.
Sean U y V dos variables aleatorias independientes con distribución c2 con n1 y n2 grados de libertad, respectivamente. La variable definida según la ecuación: 
tiene
distribución F con n1, n2 grados de
libertad.
La función de densidad de la
distribución F es:

Los parámetros de la variable F son
sus grados de libertad n1 y n2.
Las distribuciones F tienen una
propiedad que se utiliza en la construcción de tablas que es la siguiente:
Llamemos fa,n1,n2 al valor de una
distribución F con n1 y n2 grados de libertad que
cumple la condición, P(F > fa,n1,n2) = α; llamemos
f1-a,n1,n2 al valor de una
distribución F con n1 y n2 grados de libertad que
cumple la condición, P(F > f1-a,n1,n2) = 1- α. Ambos valores
están relacionados de modo que uno es el inverso del otro.
| |||||||||||





No hay comentarios:
Publicar un comentario