PRUEBAS DE HIPÓTESIS
En el análisis estadístico se hace una aseveración, es decir, se plantea una hipótesis, después se hacen las pruebas para verificar la aseveración o para determinar que no es verdadera.
Por tanto, la prueba de hipótesis es un basado en la evidencia muestral y la teoría de probabilidad; se emplea para determinar si la hipótesis es una afirmación razonable.
Prueba de una hipótesis: se realiza mediante un procedimiento sistemático de cinco paso:
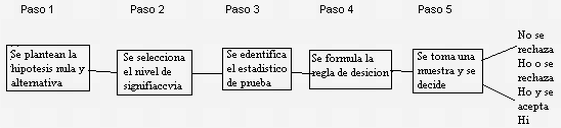
Siguiendo este procedimiento sistemático, al llegar al paso cinco se puede o no rechazar la hipótesis, pero debemos de tener cuidado con esta determinación ya que en la consideración de estadística no proporciona evidencia de que algo sea verdadero. Esta prueba aporta una clase de prueba más allá de una duda razonable.
INTRODUCCIÓN.
Dentro del de la inferencia estadística, se describe como se puede tomar una muestra aleatoria y a partir de esta muestra estimar el valor de un parámetro poblacional en la cual se puede emplear el método de muestreo y el teorema del valor lo que permite explicar como a partir de una muestra se puede inferir algo acerca de una población, lo cual nos lleva a definir y elaborar una distribución de muestreo de medias muestrales que nos permite explicar el teorema del limite central y utilizar este teorema para encontrar las probabilidades de obtener las distintas medias maestrales de una población.
Pero es necesario tener conocimiento de ciertos datos de la población como la media, la desviación estándar o la forma de la población, pero a veces no se dispone de esta información.
En este caso es necesario hacer una estimación puntual que es un valor que se usa para estimar un valor poblacional. Pero una estimación puntual es un solo valor y se requiere un intervalo de valores a esto se denomina intervalote confianza y se espera que dentro de este intervalo se encuentre el parámetro poblacional buscado. También se utiliza una estimación mediante un intervalo, el cual es un rango de valores en el que se espera se encuentre el parámetro poblacional
En nuestro caso se desarrolla un procedimiento para probar la validez de una aseveración acerca de un parámetro poblacional este método es denominado Prueba de hipótesis para una muestra.
DEFINICIÓN DE HIPÓTESIS.
Hipótesis es una aseveración de una población elaborado con el
propósito de poner aprueba, para verificar si la afirmación es razonable se
usan datos.
HIPÓTESIS NULA Y ALTERNATIVA.
Hipótesis Nula.
En muchos casos formulamos una hipótesis estadística con el único propósito de rechazarla o invalidarla. Así, si queremos decidir si una moneda está trucada, formulamos la hipótesis de que la moneda es buena (o sea p = 0,5, donde p es la probabilidad de cara).
Analógicamente, si deseamos decidir si un procedimiento es mejor que otro, formulamos la hipótesis de que no hay diferencia entre ellos (o sea. Que cualquier diferencia observada se debe simplemente a fluctuaciones en el muestreo de la misma población). Tales hipótesis se suelen llamar hipótesis nula y se denotan por Ho.
Para todo tipo de investigación en la que tenemos dos o más grupos, se establecerá una hipótesis nula.
La hipótesis nula es aquella que nos dice que no existen diferencias significativas entre los grupos.
Por ejemplo, supongamos que un investigador cree que si un grupo de jóvenes se somete a un entrenamiento intensivo de natación, éstos serán mejores nadadores que aquellos que no recibieron entrenamiento. Para demostrar su hipótesis toma al azar una muestra de jóvenes, y también al azar los distribuye en dos grupos: uno que llamaremos experimental, el cual recibirá entrenamiento, y otro que no recibirá entrenamiento alguno, al que llamaremos control. La hipótesis nula señalará que no hay diferencia en el desempeño de la natación entre el grupo de jóvenes que recibió el entrenamiento y el que no lo recibió.
Una hipótesis nula es importante por varias razones:
El hecho de contar con una hipótesis nula ayuda a determinar si existe una diferencia entre los grupos, si esta diferencia es significativa, y si no se debió al azar.
No toda investigación precisa de formular hipótesis nula. Recordemos que la hipótesis nula es aquella por la cual indicamos que la información a obtener es contraria a la hipótesis de trabajo.
Al formular esta hipótesis, se pretende negar la variable independiente. Es decir, se enuncia que la causa determinada como origen del problema fluctúa, por tanto, debe rechazarse como tal.
Otro ejemplo:
Hipótesis Alternativa.
Toda hipótesis que difiere de una dada se llamará una hipótesis alternativa. Por ejemplo: Si una hipótesis es p = 0,5, hipótesis alternativa podrían ser p = 0,7, p " 0,5 ó p > 0,5.
Una hipótesis alternativa a la hipótesis nula se denotará por H1.
- Al responder a un problema, es muy conveniente proponer otras hipótesis en que aparezcan variables independientes distintas de las primeras que formulamos. Por tanto, para no perder tiempo en búsquedas inútiles, es necesario hallar diferentes hipótesis alternativas como respuesta a un mismo problema y elegir entre ellas cuáles y en qué orden vamos a tratar su comprobación.
HIPÓTESIS SIMPLES Y COMPUESTAS.
Llamaremos hipótesis simples a aquellas que especifican un único valor para el parámetro (por ejemplo m=m0).
Llamaremos hipótesis compuestas a las que especifican un intervalo de valores (por ejemplo: m>m0 ; a< mμ2.
Llamaremos hipótesis compuestas a las que especifican un intervalo de valores (por ejemplo: m>m0 ; a< m
a) Prueba bilateral o de dos extremos: la hipótesis planteada se formula con la igualdad
Ejemplo
H0 : µ = 200
H1 : µ ≠ 200

b) Pruebas unilateral o de un extremo: la hipótesis planteada se formula con ≥ o ≤
H0 : µ ≥ 200 H0 : µ ≤ 200
H1 : µ < 200 H1 : µ > 200

En las pruebas de hipótesis para la media (μ), cuando se conoce la desviación estándar (σ) poblacional, o cuando el valor de la muestra es grande (30 o más), el valor estadístico de prueba es z y se determina a partir de:
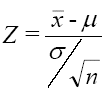
El valor estadístico z, para muestra grande y desviación estándar poblacional desconocida se determina por la ecuación:
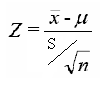
En la prueba para una media poblacional con muestra pequeña y desviación estándar poblacional desconocida se utiliza el valor estadístico t.
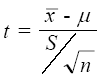
ERRORES TIPO I Y II
Un error tipo I se presenta si la hipótesis nula Ho es rechazada cuando es verdadera y debía ser aceptada. La probabilidad de cometer un error tipo I se denomina con la letra alfa α
Un error tipo II, se denota con la letra griega β se presenta si la hipótesis nula es aceptada cuando de hecho es falsa y debía ser rechazada.
En cualquiera de los dos casos se comete un error al tomar una decisión equivocada.
MATIZ DE DESICIÓN.
Una matriz de decisión es un método cuantitativo, que una empresa puede utilizar para clasificar los factores y seleccionar la mejor oportunidad de entre varias opciones. Este enfoque científico no es necesario que todas las decisiones. Cambios importantes en las operaciones del negocio, sin embargo, pueden llamar a este proceso. Pasos incluyen la definición de la solución y la fijación de prioridades y puntos son asignados, calculados, ponderadas y ascendió. Mediante este método para cada opción examinó los resultados en las puntuaciones totales para todas las opciones, con el puntaje más alto que indica un ideal, una empresa debe elegir.
Una solución ideal es uno que satisfaga o casi satisface todas las necesidades y quiere de una empresa. Propietarios y gerentes tendrán que definir las características que desean en una nueva oportunidad de negocio. La matriz de decisión requiere esto como el primer paso porque el marco para el proceso de decisión restantes comienza aquí. Factores internos y externos pueden influir en la solución ideal, que una empresa busca para completar las operaciones de sus negocio. Este proceso puede tardar más tiempo como propietarios y gerentes deben tener una clara visión para cada opción elegir.
Establecer prioridades con cada opción normalmente implica la configuración de pesos a cada característica de la primera etapa. La matriz de decisión necesita los porcentajes de cada característica para darle una puntuación final de diferentes opciones. Estos pesos pueden ser subjetivos propietarios y administradores pueden colocar figuras como 10, 15 o 25 por ciento junto a cada factor en una opción. Los factores más importantes tienen mayor peso. Todos los pesos porcentaje deben añadir a 100 por ciento para cada opción en la decisión de realizar el proceso.
Dirigentes de la empresa deben asignar puntos como la tercera parte de la matriz de decisión. Una escala básica es de uno a 10, con valores más altos de punto indicando factores más favorables entre diferentes opciones. Cada factor en el resultado de un decisión debe tener una puntuación. Asignar uno como una puntuación debería ser factores que aportan el valor mínimo para el resultado final. El uso de cinco indica que un factor no afecta significativamente el resultado final como la inclusión de factores es promedio.
Con pesos y números asignados, toma de decisiones debe calcular la puntuación de cada posible resultado. Se trata de multiplicar los porcentajes contra los números asignados para cada factor. Una vez completado, el total de todos los resultados es necesario. El resultado es un número que los propietarios y gerentes pueden comparar para todas las opciones. La opción con mayor puntuación representa la mejor oportunidad de la decisión, suponiendo que ningún sesgo existe en el sistema de clasificación de matriz de decisión.
ESTIMACION PUNTUAL.
Estimación puntual: θ= θ0
Se asigna al parámetro un valor concreto: λ = 1.25641 (como λ es la
media de una Poisson, una posible estimación es la media muestral
X =1 25641 . )
Se asigna al parámetro un valor concreto: λ = 1.25641 (como λ es la
media de una Poisson, una posible estimación es la media muestral
X =1 25641 . )
METODOS.
- Selección de caracteres dignos de ser estudiados.
- Mediante encuesta o medición, obtención del valor de cada individuo en los caracteres seleccionados.
- Elaboración de tablas de frecuencias, mediante la adecuada clasificación de los individuos dentro de cada carácter.
- Representación gráfica de los resultados (elaboración de gráficas estadísticas).
- Obtención de parámetros estadísticos, números que sintetizan los aspectos más relevantes de una distribución estadística.
MAXIMA VEROSIMILITUD.
En estadística, la estimación por máxima verosimilitud (conocida también como EMV y, en ocasiones, MLE por sus siglas en inglés) es un método habitual para ajustar un modelo y encontrar sus parámetros.
Supóngase que se tiene una muestra x1, x2, …, xn de n observaciones independientes extraídas de una función de distribución desconocida con función de densidad (o función de probabilidad)f0(·). Se sabe, sin embargo, que f0 pertenece a una familia de distribuciones { f(·|θ), θ ∈ Θ }, llamada modelo paramétrico, de manera que f0 corresponde a θ = θ0, que es el verdadero valor del parámetro. Se desea encontrar el valor 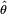 (o estimador) que esté lo más próximo posible al verdadero valor θ0.
(o estimador) que esté lo más próximo posible al verdadero valor θ0.
(o estimador) que esté lo más próximo posible al verdadero valor θ0.
Tanto xi como θ pueden ser vectores.
La idea de este método es el de encontrar primero la función de densidad conjunta de todas las observaciones, que bajo condiciones de independencia, es

Observando esta función bajo un ángulo ligeramente distinto, se puede suponer que los valores observados x1, x2, …, xn son fijos mientras que θ puede variar libremente. Esta es la función de verosimilitud:

En la práctica, se suele utilizar el logaritmo de esta función:

El método de la máxima verosimilitud estima θ0 buscando el valor de θ que maximiza 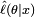 . Este es el llamado estimador de máxima verosimilitud (MLE) de θ0:
. Este es el llamado estimador de máxima verosimilitud (MLE) de θ0:
. Este es el llamado estimador de máxima verosimilitud (MLE) de θ0: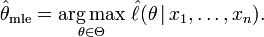
En ocasiones este estimador es una función explícita de los datos observados x1, …, xn, pero muchas veces hay que recurrir a optimizaciones numéricas. También puede ocurrir que el máximo no sea único o no exista.
En la exposición anterior se ha asumido la independencia de las observaciones, pero no es un requisito necesario: basta con poder construir la función de probabilidad conjunta de los datos para poder aplicar el método. Un contexto en el que esto es habitual es el del análisis de series temporales.
MOMENTOS.
Con las mismas notaciones usadas a la media y varianza muestral se define el estadístico momento muestral no centrado como:

Nótese que m1 es precisamente la media muestral. Análogamente se define el estadístico momento muestral centrado como:

que guarda las siguientes relaciones con estadísticos previamente definidos:
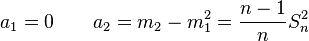
PROPIEDADES.
La suma del producto de una constante por una variable, es igual a k veces la sumatoria de la variable.
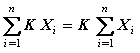
La sumatoria hasta N de una constante, es igual a N veces la constante.
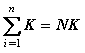
La sumatoria de una suma es igual a la suma de las sumatorias de cada término.
La sumatoria de un producto no es igual al producto de las sumatorias de cada término.
La sumatoria de los cuadrados de los valores de una variable no es igual a la sumatoria de la variable elevado al cuadrado.
ISESGADO Y CONSISTENCIA.
Conviene que los estadísticos, en su función de estimadores de los correspondientes parámetros, reúnan determinados requisitos. Fundamentalmente son:
- a)CARENCIA DE SESGO.
Un estimador (estadístico) carece de sesgo si el promedio (media) de todos los valores posibles de todas las muestras posibles de tamaño n de una población es igual al parámetro, es decir, si la media de la distribución muestral del estadístico considerado es igual al valor del parámetro. Así, la media es un estimador insesgado de μ porque se puede demostrar que la media aritmética de una distribución muestral coincide con el valor del parámetro, algo que no puede decirse, por ejemplo, o de la varianza o de la mediana de una población no distribuida normalmente.
- b) CONSISTENCIA.
Un estimador es consistente en la medida en que, al aumentar el tamaño de la muestra, (n) su valor se acerca cada vez más al parámetro correspondiente o lo que es lo mismo, si a medida que aumenta el tamaño de la muestra, las estimaciones que ésta proporciona son cada vez más próximas al valor del parámetro.
Algunos estimadores sesgados son consistentes, acercándose cada vez más sus valores a los de sus respectivos parámetros a medida que el tamaño de la muestra (n) aumenta, tal es el caso de s o s2 que son estimadores sesgados pero consistentes de la desviación típica (σ) o de la varianza (σ2) de la población.
ESTIMACION POR INTERVALOS DE CONFIANZA.
Sea desconocida la media poblacional de una cierta variable que deseamos estudiar, sacamos una muestra y se trata de obtener un intervalo (L1,L2) de forma que tengamos una probabilidad alta (1-alfa)% de que la media poblacional esté en ese intervalo. El nivel de confianza del intervalo (1-alfa)% lo fijamos nosotros., se suele trabajar con 95% y a veces con 99% o el 90%; es decir, con probabilidad 0.05, 0.01 o 0.1.
Si se cumple una de las siguientes hipótesis:
El intervalo de confianza para la media poblacional es:
Donde z es el valor que en la distribución N(0,1) deja a su derecha un área de alfa/2,
|
Actividad 15. A una muestra de 150 estudiantes de 2º de Bachillerato n cierta ciudad correspondió una estatura media de 1,73 m, siendo la desviación típica de 4,95 cm. Estima la estatura media de la población, y calcula, para un nivel de confianza del 99%, el intervalo de confianza para la media.
En primer lugar comprueba se cumplen las hipótesis, calcula el valor de alfa y en la tabla de la N(0,1) encuentra el valor de z que deja a su derecha un área de alfa/2. Anótalo en el cuaderno de trabajo.
A continuación introduce los datos en la escena siguiente y se calculará el intervalo de confianza. Cambia la escala si el gráfico no se ve correctamente.
Observando el intervalo podemos apreciar cual será el error máximo cometido. ¿Cuál es? Escribe la fórmula del error máximo cometido.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Por tanto podemos estimar la estatura media de la población, con un nivel de confianza del 99%, en 1,73 cm, con un error máximo de 1.04. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Actividad 16. Se considera los siguientes tiempos de reacción de un producto químico en segundos:
Obtener un intervalo de confianza del 90% para el tiempo medio de reacción suponiendo que la variable es normal.
Utiliza la primera escena para calcular la media y la desviación típica, recuerda que es la raíz cuadrada de la varianza, después utiliza la escena anterior par calcular el intervalo de confianza.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ESTIMACIÓN POR INTERVALOS DE CONFIANZA PARA LA PROPORCIÓN | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sea p desconocida la proporción de elementos en la población pertenecientes a una categoría C, sacamos una muestra y se trata de obtener un intervalo (L1,L2) de forma que tengamos una probabilidad alta (1-alfa)% de que la proporción esté en ese intervalo.
Si se cumple una de las siguientes hipótesis, y que habrá de comprobarlas en todos los problemas son:
En estas condiciones se obtienen los siguientes intervalos según el tamaño de la muestra:
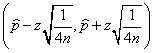
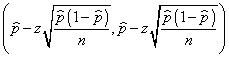
Donde
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Actividad 17. En cierta población se seleccionó aleatoriamente una muestra de 300 personas a las que se les sometió a cierto test cultural. De ellas, 225 resultaron aprobadas. Teniendo en cuenta esta información, estimar el porcentaje de persona de esa población que resultarían aprobada si se las sometiera a dicho test cultural. Obtener, con un nivel de confianza del 95%, un intervalo de confianza para la proporción.
Primero calcula, utilizando la escena segunda, cual es el valor de la proporción en la muestra.
Después calcula el valor de alfa y en la tabla de la N(0,1) encuentra el valor de z que deja a su derecha un área de alfa/2.
PROCEDIMIENTOS DE PRUEBA DE HIPOTESIS.
El jefe de la Biblioteca Especializada de la Facultad de Ingeniería Eléctrica y Electrónica de la UNAC manifiesta que el número promedio de lectores por día es de 350. Para confirmar o no este supuesto se controla la cantidad de lectores que utilizaron la biblioteca durante 30 días. Se considera el nivel de significancia de 0.05
Datos:
Solución: Se trata de un problema con una media poblacional: muestra grande y desviación estándar poblacional desconocida.
Paso 01: Seleccionamos la hipótesis nula y la hipótesis alternativa
Ho: μ═350
Ha: μ≠ 350
Paso 02: Nivel de confianza o significancia 95%
α═0.05
Paso 03: Calculamos o determinamos el valor estadístico de prueba
De los datos determinamos: que el estadístico de prueba es t, debido a que el numero de muestras es igual a 30, conocemos la media de la población, pero la desviación estándar de la población es desconocida, en este caso determinamos la desviación estándar de la muestra y la utilizamos en la formula reemplazando a la desviación estándar de la población.
Calculamos la desviación estándar muestral y la media de la muestra empleando Excel, lo cual se muestra en el cuadro que sigue.
Paso 04: Formulación de la regla de decisión.
La regla de decisión la formulamos teniendo en cuenta que esta es una prueba de dos colas, la mitad de 0.05, es decir 0.025, esta en cada cola. el área en la que no se rechaza Ho esta entre las dos colas, es por consiguiente 0.95. El valor critico para 0.05 da un valor de Zc = 1.96.
Por consiguiente la regla de decisión: es rechazar la hipótesis nula y aceptar la hipótesis alternativa, si el valor Z calculado no queda en la región comprendida entre -1.96 y +1.96. En caso contrario no se rechaza la hipótesis nula si Z queda entre -1.96 y +1.96.
Paso 05: Toma de decisión.
En este ultimo paso comparamos el estadístico de prueba calculado mediante el Software Minitab que es igual a Z = 2.38 y lo comparamos con el valor critico de Zc = 1.96. Como el estadístico de prueba calculado cae a la derecha del valor critico de Z, se rechaza Ho. Por tanto no se confirma el supuesto del Jefe de la Biblioteca.
Procedimiento de prueba de hipótesis 2 parámetros.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
INDIVIDUO
|
ANTES XI
|
DESPUES YI
|
di
|
di2
|
|
1
2
3
4
5
6
7
8
9
10
11
12
|
201
231
221
260
228
237
226
235
210
267
284
201
|
200
236
216
233
224
216
296
195
207
247
210
209
|
- 1
+ 5
- 5
- 27
- 4
- 21
- 30
- 40
- 33
- 20
- 74
+ 8
|
1
25
25
625
16
441
900
1600
1089
400
5176
64
|
|
TOTAL
|
|
|
-242
|
10.766
|
- Pruebas no paramétricas.
Las pruebas de hipótesis hacen inferencias
respecto a los parámetros de la población, como la media. Estas pruebas
paramétricas utilizan la estadística paramétrica de muestras que provinieron de
la población que se está probando. Para formular estas pruebas, hicimos
suposiciones restrictivas sobre las poblaciones de las que extraíamos las
muestras. Por ejemplo: suponíamos que las muestras eran grandes o que provenían
de poblaciones normalmente distribuidas. Pero las poblaciones no siempre son
normales.
Los estadísticos han desarrollado técnicas
útiles que no hacen suposiciones restrictivas respecto a la forma de las
distribuciones de las poblaciones. Éstas se conocen como pruebas sin
distribución, o pruebas no paramétricas. Las hipótesis de una probabilidad no
paramétrica se refieren a algo distinto del valor de un parámetro de población
Ventajas de los métodos no paramétricos.
- No requieren que hagamos la suposición de que
una población está distribuida en forma de curva normal u otra forma
específica.
- Generalmente, son más fáciles de efectuar y
comprender.
- Algunas veces, ni siquiera se requiere el
ordenamiento o clasificación formal.
Desventajas de los métodos no paramétricos.
- Ignoran una cierta cantidad de información
- A menudo, no son tan eficientes como las
pruebas paramétricas. Cuando usamos pruebas no paramétricas, efectuamos un
trueque: perdemos agudeza al estimar intervalos, pero ganamos la habilidad
de usar menos información y calcular más rápidamente.
No hay comentarios:
Publicar un comentario